
The transformation from Web 1.0 into Web 2.0 has been a great achievement towards user interaction on the web. Coined by Tim O’Reilly, “Web 2.0 is about how technology works and how e technology is used in real-world effects”, Governor, J et al (2009). Characterised as a read/write web, the users are content creators, Krishnamurthy, B and Cormode, Gramham (2008). Facebook, Twitter, Flicker, blogs and wikis all come under the heading of Web 2.0 in order to facilitate user interaction and participation. New technologies and standard as those mentioned below fuelled Web 2.0 and made it possible for libraries to change the delivery of their services to users.
The criteria outlined for web 2.0 included; the sharing of media and content and the use of web standards such as validated XHTML and Cascading Style Sheets (CSS), the integration of emerging web technologies such as Asynchronous JavaScript and XML (AJAX), Really Simple Syndication (RSS) and Application Programming Interfaces (APIs), Curran, Kevin et al (2007).
AJAX (Asynchronous JavaScript and XML), is a group of interrelated web development techniques used on the client side to create interactive web applications, Wikipedia (2010). It uses programs like JavaScript[1], DHTML[2], XML[3] CSS[4], DOM[5] and XMLHttpRequest[6], to allow users to manipulate information on websites in real time e.g. Google maps. A combination of HTML and CSS is used to mark up style and information on websites. The DOM is accessed with JavaScript to dynamically display information, and to allow the user to interact with the information presented. JavaScript and the XMLHttpRequest object provide a method for exchanging data asynchronously between browser and server to avoid full page reloads, Wikipedia (2010). AJAX works directly from the browser and does not require plug ins, what?is.com (2010).
API is defined as is the specific method prescribed by a computer operating system by which a programmer writing an application program can make requests of the operating system or another application, what?is.com (2010). An API is implemented by applications, libraries, and operating systems to determine their vocabularies and calling convention, and is used to access their services, Wikipedia (2010). API and web services allow users to integrate web services on their websites and thus create mash ups, e.g. http://www.student.city.ac.uk/~abjm507/mashup.html.
RSS (Really Simple Syndication) is a family of web feed formats used to publish frequently updated works—such as blog entries, news headlines, audio, and video—in a standardized format, Wikipedia (2010). It uses XML to describe date and is embedded in the browser. Users can subscribe to RSS feeds and be regularly updated with current feeds on a daily basis.
Web services like XHTML and CSS involve transferring information over the internet that can be read by machines. XHTML is (Extensible Hypertext Markup Language), it describes the content in terms of what data is being described, what?is.com (2010). For example <title>, <name> tags can be used to give structure to information. Having this ability makes it easier for information over the internet to be shared according to common standards of describing data. CSS describes how web pages can be viewed over the internet, and the how web pages will look.
These technologies and standards makes adding content to pages easier for users without having programming skills. Users can upload pictures, text and graphics to their websites, social networking websites, blogs and twitter account easily. This revolution on the internet, which led to increased user interaction, feedback and participation and is now a critical part of any website’s success.
Library 2.0 was coined by Michael Casey in his blog LibraryCrunch in 2005, its concept follows from Web 2.0 in that user participation and feedback is its main objective. Like Web 2.0, user connectivity plays as key role in Library 2.0. The statement, “Browser+Web 2.0 applications+connectivity = full featured OPAC”, Curran, Kevin et al (2007), is key feature of its objectives and displays how new technologies like AJAX changed library services. With the introduction of web 2.0 technology, libraries were able to replace their card catalogue with an Online Public Access Catalogue (OPAC). The catalogue became digital and access to and other services extended after closing time. Users are allowed to search, borrow, reserve, and renew items online. The library catalogues also incorporated images in OPAC. Items retrieved from a search query include a picture of the item alongside the catalogue details, like on the Amazon website, http://www.amazon.co.uk/?tag=mh0a9-21&hvadid=460967336&ref=pd_sl_7xj89b8y3o_e, Amazon (2010). Also, the main pages of Library websites includes Google maps of their location and links to online databases, as well as downloadable e books. This resulted in more user interaction between users and libraries.
Web 2.0 technology enabled libraries to generate much more user participation Curran, Kevin et al (2007). OCLC is an online world catalogue that allows libraries to add, edit and upload new records of item. Libraries subscribe to OCLC and benefit from copying cataloguing i.e. where instead of creating new records for each item, records are downloaded from OCLC and edited to suit individual libraries. Records can be upload to OCLC which do not exists in their catalogue. When this is done, libraries get a rebate on their account. This encourages participation within the library community. With library software e.g. AutoLib, libraries can subscribe to AutoLib SAINT and can download pre existing catalogue records of item. Once a barcode is scanned into the software the record is automatically inserted into the catalogue fields and a record can be created. This saves time cataloguing items. Records can also be edited for specific libraries.
Library user participation comes in the form of feedback from users on, blogs, twitter and wikis. These new interactive websites now play a significant role in where information is disseminated. Indeed there are several blogs about libraries’ current awareness issues that encourage comments and feedback from peers and the public e.g. Librarian in Black, . http://librarianinblack.typepad.com. Also, most libraries have their own twitter page for which followers can follow and get current information about their favourite libraries and leave feedback about their services. Examples of this can be found on, Temple University Library (http://blog.library.temple.edu/liblog/archives/events/), where their blog provides a place for news, events and discussion and Saint Joseph County Public Library, (http://www.libraryforlife.org/) where open source wiki software is used to create “a successful guide that facilitates customer feedback”, Casey (2006) .
Although there has been a signification progress in libraries getting on board with new technology and current trends in Web 2.0 era, it seem that despite their best effort, the value of libraries is fading. With the current climate of recession and in the wake of the current Government advocating cuts for a 1/3 of public library closures, Library 2.0 is does not seem to as successful as Web 2.0. Questions like, why borrow books when you can buy it? or if information is freely and widely available online why go to a library for information?, are around in spite of technological advances in Libraries. One suggestion to compete with online booksellers came from a report titled Do libraries matter? The rise of Library 2.0, in which a suggestion to incorporate libraries’ information on online bookseller’s websites like Amazon, Chad, Ken and Miller, Paul (2005). Where a buyer can choose to either buy an item new, used or borrow for free from local libraries. This would have given libraries especially public libraries a chance to market their services to people who did not visit libraries and a chance to increase people’s awareness of them. Obviously this did not happen. Booksellers and internet cafe still hold a real threat to libraries. These questions like the above are ongoing and there seems to be no real decisive answer on how to deal with them. Deeper thinking and creative methods are needed to propel the value of Libraries into society consciousness and a change in the paradigm may be necessary.
However, new technology and standards are still advancing and it may new hope for the library profession in the form of a semantic web. Tim Berner’s-Lee said that “semantic web is not about understanding data; it is about putting data onto the Web to make it available so that we can access and use it”, Powell, S (2006).
A diagram of the semantic web as below:

Tim Berners-Lee Semantic Web Layer Cake, Wikepedia (2010)
http://en.wikipedia.org/wiki/File:Semantic-web-stack.png
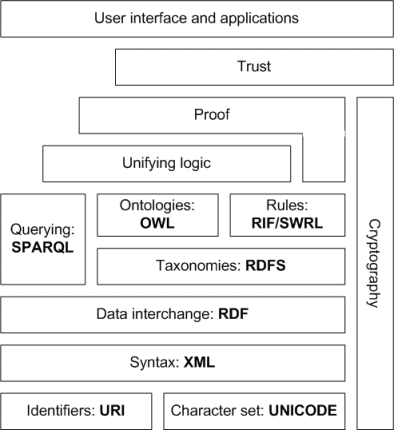
Tim Berners-Lee Semantic Web Layer Cake, Wikepedia (2010)
http://en.wikipedia.org/wiki/File:Semantic-web-stack.png
{kind=link}
Work is still in progress in building a semantic web, and it’s a basically a concept right now, but W3C[7] is working towards developing and creating it. The purpose of it will be ultimately to allow data to be read by machines and which will allow search engines “to significantly improve the efficiency and effectiveness of users to access information on the web”, Goker, A & Davies, J (2009).
From the diagram the main key component are OWL (Web ontology language) and RDF (Resource description framework). Information has to be given meaning to become semantic. RDF comprises of triples which are statements that include a, <subject, Predicate and Object>. “The subject denotes the resource, and the predicate denotes traits or aspects of the resource and expresses a relationship between the subject and the object”, Wikipedia, (2010). RDF is express in XML format. By creating RDF triples deductions can be made about data and using RDF schema a language can be created to form taxonomies[8]. Web Ontology Language (OWL) is a family of knowledge representation languages for authoring ontologies[9]. They can create linked data and can be represented as shown below:

Semantic web is built upon technologies that can facilitate future semantic searching. Currently two problems associated with IR are synonymy and polysemy, Goker, A. and Davies, J (2009). When users do a search query they use terms which they think might be in documents. This brings up a problem in retrieving documents, in that “not all documents will use the same words to refer to the same concept”, Goker, A. and Davies, J (2009). This then means that simple keyword searching would not bring up all the documents that are relevant. This problem is termed “index term synonymy, Goker, A. and Davies, J. (2009) Polysemy relates to the problem of ambiguity with words. Some words have multiple meaning, and since search engines cannot distinguish what term is relevant to the user, this can then lead to irrelevant information being retrieved, Goker, A. and Davies, J, (2009). Another limitation of current IR is that it cannot handle queries that “require reasoning, extraction and explicit structuring”, Goker, A. and Davies, J.
By creating a semantic web, data will be tagged and organised in a machine readable format, this will allow search engines to perform more efficient searches since ambiguity about terms will be less. W3C gives an example of how a semantic web would look like on their website, http://www.w3.org/2001/sw/sweo/public/UseCases/. The right hand side of the page has the index terms listed. Searching can become easier and search engine more intelligent at retrieving documents, when data is tagged and organised.
When the Semantic web is fully developed it would have an impact in quality of IR. This would indelibly have a knock-on effect on libraries. Maybe it would add value to the profession of Librarians and Information professionals, since the skill of creating taxonomies and tagging data lies in the information field. Or alternatively, the services of libraries and information centres may continue to diminish, since search engines will be able to give more exact and relevant information, so why depend on libraries? Hopefully the value of libraries will be seen as relevant and it services can be integrated with technology and not get diminished by it. Think it will depend on how best Information professionals can use their skill and knowledge to re design core services and keep users interested in them.
[1] JavaScript is an interpreted programming or script language from Netscape, ,what?is.dom (2010). It is used in web pages to change formatted date on a web page, change text or graphic with a mouse roll over.
[2] Dynamic HTML is a collective term for a combination of Hypertext Markup Language (HTML)tags and options that can make Web pages more animated and interactive than previous versions of HTML, what?is.dom (2010).
[3] XML (Extensible Markup Language) is a flexible way to create common information formats and share both the format and the data on the World Wide Web, intranets, and elsewhere, what?is.dom (2010).
[4] Cascading Style Sheets is a style sheet language used to describe the presentation semantics (the look and formatting) of a document written in a markup language. Its most common application is to style web pages written in HTML and XHTML, but the language can also be applied to any kind of XML document, Wikipedia (2010)
[5] Document Object Model (DOM), a programming interface specification being developed by the World Wide Web Consortium, lets a programmer create and modify HTML pages and XML documents as full-fledged program objects, what?is.dom (2010).
[6] XMLHttpRequest, also called XHR, is an application program interface (API) that was first used by Microsoft in version 5.0 of its Internet Explorer Web browser to function as an Active X object, what?is.dom (2010).
[7] (W3C) The World Wide Web Consortium is an international community where Member organizations, a full-time staff, and the public work together to develop Web standards.
www.w3.org (2010)
[8] Taxonomy is the science of classification according to a pre-determined system, with the resulting catalogue used to provide a conceptual framework for discussion, analysis, or information retrieval, what?15.com, (2010)
[9]In computer science and information science, an ontology is a formal representation of knowledge as a set of concepts within a domain and the relationships between those concepts. It is used to reason about the entities within that domain, and may be used to describe the domain, Wikipedia (2010).
[i]References:
Articles
Curran, K., Murray, M. and Christian, M. (2007) Taking the information to the public library through Library 2.0, Library Hi Tech, 25(2) pp.288-297.
Powell, S., (2006) An interview with Tim Berners-Lee, Emerald Now Newsletter
Tho, Q.T., Fong, A.C.M. and Hui, S.C. (2007) A scholarly semantic web system for advanced search functions, Online Information Review, 31(3), pp.353-364.
York, S and Struder (2005) Semantic web technologies for digital libraries, Library Management, 26(4/5), pp. 190-195.
Books
Goker, A and Davies, J (ed). (2009). Information retrieval: searching in teh 21st century. Chichester: John Wiley.
Governor, J, Hinchcliffe, D and Nickull, D. 2009, Web 2.0 architectures. California: O’Reilly.
Websites
Amazon.com (2010) Available: http://www.amazon.co.uk/?tag=mh0a9-21&hvadid=460967336&ref=pd_sl_7xj89b8y3o_e [10 December 2010]
Asgarali-Finn, S. (2010) DITA session 2 assignment. Available: http://www.student.city.ac.uk/~abjm507/mashup.html [10 December 2010]
Chad, K., Miller, P. (2005), Do Libraries Matter? White paper. Available: http://www.talis.com/applications/downloads/white_papers/DoLibrariesMatter.pdf [10 December 2010]Cormode, Graham and Krishmamurthy, B. (2008) Key differences between Web 1.0 and Web 2.0. Available: http://www2.research.att.com/~bala/papers/web1v2.pdf [10 December 2010]
Casey, M. (2005), LibraryCrunch, Available: http://www.librarycrunch.com/2005/10/working_towards_a_definition_o.html [10 December 2010]Houghton-Jan, S (2010), Librarian in Black, Available: http://librarianinblack.typepad.com/ [ 10 December 2010]
Saint Joseph County Public Library (2010), Available: http://www.libraryforlife.org/ [10 December 2010]
Temple University Library (2010), Available http://blog.library.temple.edu/liblog/archives/events/ [10 December 2010]